-
Core Dataのベストプラクティス
Appのユーザー数や機能が増えるにつれ、解決すべき新しい問題が生じる可能性があります。Core Dataは、過去数年にわたり大きな変化を遂げてきたパワフルなツールです。並行性や永続性の履歴を活用する方法といった、Core Dataの最新のベストプラクティスや、使い慣れたテクノロジーを使って一般的な問題をテストおよび解決する方法について紹介します。
リソース
-
このビデオを検索
(音楽)
こんにちは (拍手) Core Data Best Practicesへようこそ Core Dataのスコット・ペリーと ニック・ジレットがお届けします
まず初めに
進化し続けるCore Dataについて 簡単にご紹介します 次に 永続コンテナにおける 拡張ポイントを活用し アプリケーションを より簡単に進化させる方法
アプリケーションの要求や データ量に応じて モデルを進化させる方法
規模に関わらず パフォーマンスを維持する方法 こちらはニックがお話しします
トランスフォーマやデバッグ テストにも触れます
アプリケーションを 作ってみましょう 投稿した写真にコメントが付くのは うれしいものです たとえニックからの 仕事関係のコメントでもね
データの保存先は オンライン上でもいいですが 旅行先だと 通信が不安定なこともあります ローカルへの保存が賢明でしょう
オブジェクトグラフが インスタンスや その間の関係により形成されます これらをディスク上に 保存するわけですが そこでCore Dataの出番です
これを使って まずモックを ストアが読み込める― 管理オブジェクトモデルに 変換します フィールドが必要です 属性は画像データや 投稿時間などです 関係も必要になります ディスク上でのデータの長期保存は 簡単ではありません Core Dataによる 永続ストアコーディネータは アプリケーションのモデルを ストアのバージョンと比較して 移行を自動で行ってくれます 管理オブジェクトコンテキストは 安全かつ高速で 予測可能なアクセスを可能にします クエリジェネレーションや コネクションプーリングなどの― 処理中でも対応できます
ここでモデルを見つけ それを読み込み ストアの場所を決めますが App配信後のエラーパスは ほぼエラーにならないので Core Dataによるコンテナタイプで ボイラープレートは 大幅に省略できます 永続コンテナがメインバンドルから モデルを読み込み 一定の場所に保存するのです
スタック全体がカプセル化され 共有されたメインキューの― ビューコンテキストにも有用です バックグラウンドの パフォーマンスを上げるための ファクトリメソッドにも役立ちます アプリケーションが大きくなっても 対応できます モデルレイヤーを 独自のフレームワークに 組み入れたい時でも 新しいフレームワークターゲットを Xcodeで作り コードを移すだけです しかしモデルを 新しいターゲットへ移す時 ターゲットは 新しいフレームワークへ移動します 正しい動きですが NSPersistentContainerが モデルを捜せなくなります デフォルトでは チェックの対象は メインバンドルだけです スタックを回転させるたびに 全てのバンドルを調べていては 動作が遅くなるからです
対処法は? フレームワークバンドルから モデルを再び取り出し コンテナの他のイニシャライザを 使う手もありますが NSPersistentContainerなら 検索対象のバンドルを変更できます
NSPersistentContainerは モデルを捜す際に サブクラスの型を ヒントとして使います サブクラスを作成すれば これを利用できます 中に何か書く必要はありません モデルを使うコンテナの コード設定にサブクラスが採用され 永続コンテナが バンドルから モデルを見つけ出します
ディスク上のデータの編成も 改善されていたら 一層すばらしいと思いませんか?
新しい永続コンテナは 自動移行するSQLiteストアの― ストアディスクリプションが デフォルトで備わっています それは結構ですが 新しいフレームワークと― アプリケーションの融合し過ぎは 避けたいですね モデルを見つけるのが 容易になったところで この点も改善してみましょう
ストアの場所を強制的に変えるには persistentStoreDescriptionsの 中のURLを 直接 書き換えればいいでしょう ただし今回は NSPersistentContainerが 永続ストアのディスクリプションを 作成する際に defaultDirectoryURLメソッドを 呼び出します オーバーライドもされます appendingPathComponentも 有効です ストアを別々の場所に とどめておくための キャッシュやスタック用に コンテナを構成する手もあります
ここで アプリケーションや View Controllerについて 実際に見ていきましょう
あることに特化した View Controllerです 左は私のポスト 右は全ての作成者のポストです 重複しているので 半分のコードで済みそうです
片方では複数のポストを表示させ 片方では1つだけ表示させます モデルオブジェクトを取る 2つのView Controllerの境界を うまく設定すれば可能です
各View Controllerは モデルパラメータにより構成され 表示するポストによって ビューを 細かくカスタマイズできます
リストビューには フェッチ要求を取得させ ディテールビューには 管理オブジェクトを取得させます
管理オブジェクトコンテキストも 必要です ビューコンテキストか 他の メインキューコンテキストです View Controllerを汎化する この方法は ユーティリティのデータ型にも 非常に有効です URLやシリアル化されたデータを バックグラウンドワークの コントローラに渡します バックグラウンドの コンテキストを使って 更新済みの 管理オブジェクトに変換するのです
私たちは独自のイニシャライザを 持っているため コントローラの生成を パラメータに要求するだけですが View Controllerへの 境界変数の組み入れ方は?
prepareメソッドは セグエでオーバーライドできます destinationViewControllerへの 参照も取得できます ストーリーボードかNIBがあるなら destinationViewController用の コードはできているので 表示する前に プロパティを 設定すればいいだけです 手動で行うなら 境界条件を明確に定義する― イニシャライザを 書いてもいいでしょう
これで フェッチ要求と コンテキストが準備できました しかし フェッチ要求に もう少し手を加えて より優れたパフォーマンスを 発揮させましょう
今回は全データを見せたいので フェッチリミットの設定より バッチ処理のほうが有効です 私たちはView Controllerの キャパシティを知っています
フェッチ要求には こうした選択肢を 1つは用意しておくべきです
これでフェッチ要求を リストビューに変換できます では UIを常に 最新の状態に保つ方法は? 役立つのが フェッチ結果コントローラです あらゆるプラットフォームで 利用でき デリゲートプロトコルと ビューの間にアダプタを書けば 導入することができます 必要なのはフェッチ要求と コンテキストだけです より進化したリストビューの コンセプトにも有用です
ポストは 日を基準に グループ分けできます 計算済みプロパティでXcodeが 生成したポストタイプを拡張し フェッチ結果コントローラの イニシャライザに 名前を渡すのです 有効な手段ですが View Controllerが もっと複雑だったら? 日ごとのポストを グラフ化して表示したい場合は?
フェッチ要求の実力を 侮ってはいけません 私は先月 1日に40枚の写真を ポストしましたが ストアから瞬時に取り出すには 十分すぎる量でした
定義しておいたdayプロパティが エンティティの一部であれば フェッチ要求で 日を基準に ポストをカウントできるでしょう 段階は3つあります まず 範囲を30日間に設定します
次に 同じ値のday属性を持つ 全ての結果をグループ化します フェッチしているのは オブジェクトの集合体なので 結果の型を ディクショナリに変えます
最後に 各グループの オブジェクトの数を表す― 計算式を定義して フェッチ要求にその数を返させます
返される30の結果が グラフ上で点で表されます
これはCore Dataが生成する SQLiteクエリです 皆さんがクエリを書く時と 同じですね Core Dataは多くの関数式を 最適なデータベースクエリに 変換できます クエリによるグループは 集計関数を使うことができ スカラークエリは 通常のフェッチ要求のように ABS関数などの 日付関数が使えます
NSExpressionでできることを もっと知りたい方は 使える関数のリストを ご確認ください
フェッチ要求は 関数式を使うことで活躍しますが 依然 SQLiteはメモリを通して 全てのポストを読み込みます もし 対象となるポストが 1か月分だけならいいですが 範囲がもっと広い場合は? 1年分ならどうでしょう? データ量が ケタ違いだったとしたら? この例では フェッチ要求は 5万件のポストを1件ずつ数えます それでは間に合いません ビューとモデル間のミスマッチには 非正規化が必要です
冗長データを追加する 非正規化により 読み込みパフォーマンスを 改善できます データベースインデックスが いい例です カウントメタデータを ストアに加えれば グラフのパフォーマンスを 再び向上させることができます 今回のモデルについて 見ていきましょう 2つの属性を持つエンティティと メンテナンスが必要です フェッチ要求を改善し 何年分ものデータをカバーできます この程度の非正規化で十分なのです View Controllerに渡した フェッチ要求? すごくシンプルです 他のリストビューに渡した フェッチ要求とそう変わらず グラフのビューと ほぼ同じに見えます
メンテナンスとは? ポスト時のインクリメントと 削除時のデクリメントです 確実な解決法は コンテキストの退避に応じて 計算をアップデートすることです
管理オブジェクトの contextWillSave通知と 全てのポストに影響する関数を 登録して カウントをインクリメントしても いいでしょう 別のループには 投稿日に応じて カウントをデクリメントさせます コンテキストは データベースに 作用する前に影響を受け 機能が向上していきます Core Dataがあれば 小さなアプリケーションでも 夢のような物に 進化させることができるのです ニック (拍手) ありがとう (拍手) アプリケーションは 規模が大きくなるにつれ 複雑になっていきます しかし 規模を大きくするのは 重要なことです 規模を大きくしていく中で いかに機能性を上げ 付加価値を高められるかが 私たちの存在意義だからです
しかしアプリケーションによって その過程は異なり 顧客体験や作り手の意図とも 密接に関わってきます アプリケーションの構造が 複雑になるほど カオスを招く危険性が高くなります Core Dataで このカオスを うまくコントロールしましょう 予測可能な動作を設定し 顧客体験に応じた 柔軟なコンテナを作るのです
具体的には? メトリクスに関しては いくつかの切り口が考えられます 1つ目は 顧客に応じたものであること 通常は顧客が体験することを 指します 一貫したインターフェイスや レスポンシブなスクロールビュー
楽しさとも関係します
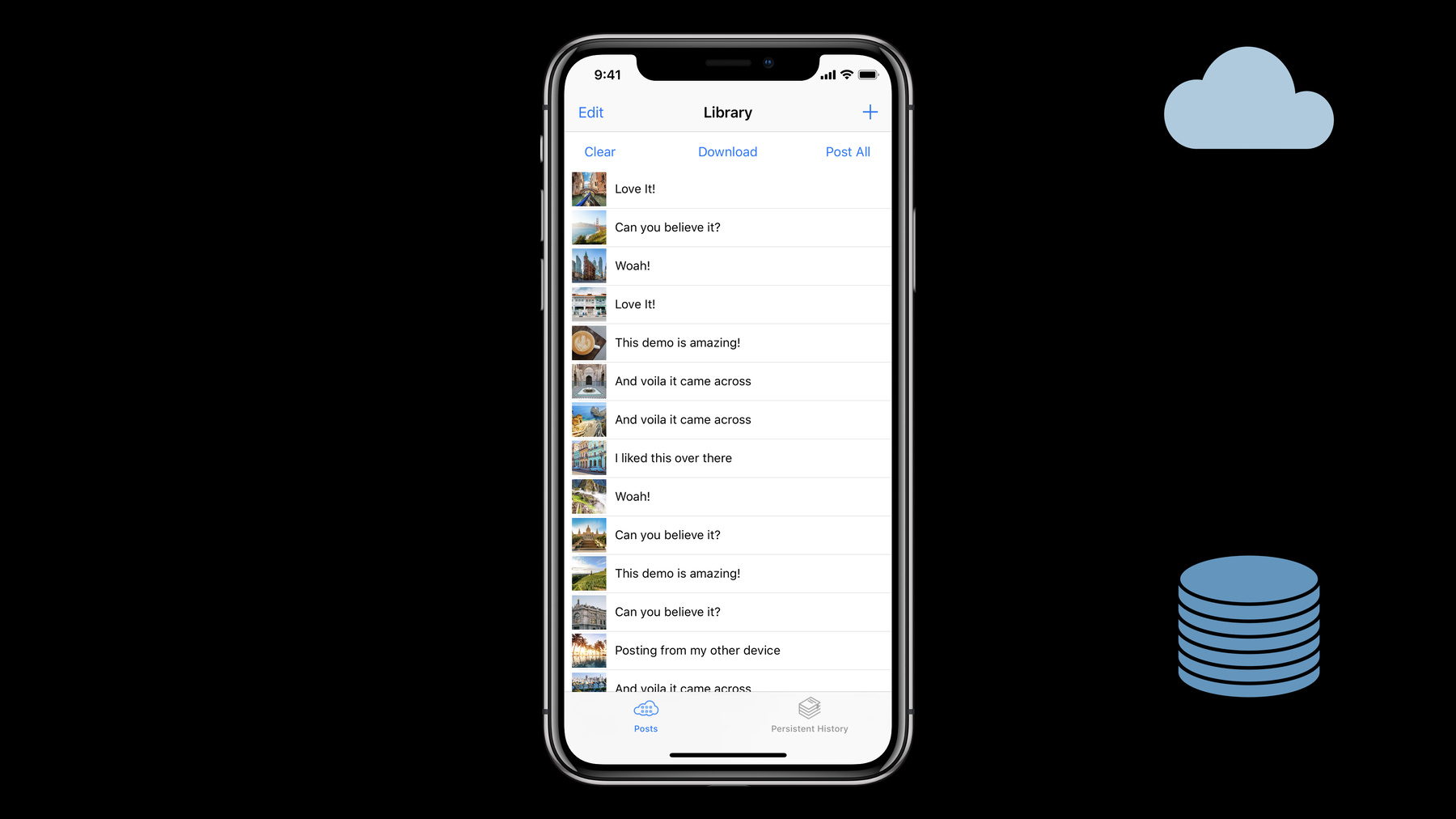
これらはエンジニアには 捉えにくいため― エンジニアリングメトリクスに 落とし込みます ピーク時のメモリ消費量や タスク実行時のバッテリーの消耗 CPU時間は どれぐらいかかっていて I/Oは どのくらい行われているか より具体的に ご説明しましょう 昨年ご紹介した デモ用のアプリケーションですが 今回用に修正を加えてあります 顧客が取る行動は いくつか考えられます まず+ボタンで ポストを1件 データベースに加えること 待機中のデータを サーバから ダウンロードすることもできます
新規で全てアップロード する場合はPost Allです インタラクションの組み合わせは かなり小規模なものですが これが一斉に起こると― カオスになります
たとえ小さな動作でも 一斉に起こると アプリケーションの状態に 様々な影響を及ぼします 最悪の場合 ユーザ体験は このようになります エンジニアにすら理解できないほど 不完全な状態です
そこで有用なのが クエリジェネレーションです これは2016年のセッションでも ご紹介しました 詳しく知りたい方は ぜひ そちらもご覧ください これにはWALジャーナルモードと SQLiteが欠かせません 管理オブジェクトコンテキストを 競合する動作から切り離します ユーザが行うであろうものの― まだ準備できていないアクションに 役立つものです クエリジェネレーションが提供する データベースのビューは フェッチする際に 他のコンテキストに関わらず 同じ結果を返します
必要なコードは1行だけです テーブルビューのリロード時は このように クエリジェネレーションと共に NSManagedObjectContext setQueryGenerationFromトークンの 呼び出しを挿入します
アップデートする際は
通常どおりNSManagedObjectContext DidSave通知を使います
これにより 然るべきタイミングで 変更を加えることができます
データがUIと関連していない時は? コメントを ダウンロードするような場合です そうしたデータには インターフェイスに 現れてほしくありません ユーザに分からないような変更も 困ります そこでヒストリートラッキングで アップデートをフィルタします 永続ヒストリートラッキングは iOS 11とmacOS 10.13で 新しく導入されました 昨年のセッションでも ご紹介していますので 基本的な特徴を知りたい方は そちらをご覧になってみてください
永続ヒストリートラッキングは 各トランザクションの 永続レコードを得る上で有効です 理由は いくつかあります ただ このセッションで 考えたいのは NSPersistentHistoryChangeです これはchangedObjectIDと updatedPropertiesを与えます また NSPersistentHistory Transactionもです これはchangesと objectIDNotificationを与えます
changesを見ていきましょう これらはデータベースに 挿入されているポストです このテーブルビューを見ると UIをリフレッシュ したくなるでしょう objectIDNotificationで それができます これらはNSManagedObjectContext DidSave通知に類似し 同じAPIを使ってマージされます
ユーザアップデートに 現れてほしくないコメントを ダウンロードしてしまった場合は
フィルタできます
与えられたトランザクションから changesをフィルタし ポストエンティティとの関連を 判断します
これでUIの リフレッシュを避け ユーザへの不要な負担を 回避できます ここではポストコンテンツを 少し使っているだけです 具体的には たった2つのプロパティです imageとtitleです
エンティティによる フィルタにとどまらず ヒストリーの変更を使い updatedPropertiesでもフィルタ ユーザからも視認できて ユーザ体験に的を絞った― アップデートを実現できるのです
新たなインタラクションにも Core Dataは役立ちます 編集作業の中には データ量が増えるほどに より多くのコストが かかるものもあります シンプルなフォトブラウザを 例に取ります アプリケーションの規模が 大きくなるにつれ 繰り返しのタスクを より簡単に行いたくなるものです 例えば複数選択などです
Core Dataはバッチ処理で これをサポートできます ほんの数行のコードで 写真を選別できるようになります
また コードを1行書けば データベースのレコードを パージもしくは削除できます オブジェクトをメモリ上で フォールトするよりも はるかにうまくいく処理です 例えば削除する際 NSManagedObject.deleteを呼び出す 従来の方法は データベースのレコードの サイズに合わせて用いられます オブジェクトを削除し メモリがフォールトされると コストは増え データベースも 大きくなっていきます しかし バッチ処理なら わずかなメモリの中で 同じ変化をもたらせます そしてデータが増加する時 望む曲線が得られます データが大きくなるほど メモリは少なく済むのです 1000万行で 従来の 削除時のメモリの7%程度です
これはリソースの節約に 非常に役立つ手段です
しかし バッチ処理の問題点は 保存通知を作らないため 扱うのが難しいということです 再びヒストリートラッキングの 出番です 永続ヒストリートラッキングでは バッチ処理を行う際に トランザクションを データベースからフェッチできます objectIDNotificationを使い 保存通知と同機能の Notificationを生成できます こうして アプリケーション内の フェッチ結果コントローラなどは それらの通知を 徐々にアップデートできます
以上がCore Dataによる 増加するデータの管理方法です では実際のワークフローは? アプリケーションをビルドしたり テストしたりする上で Core Dataは どう役立つのでしょう?
必ず今日から あなたの助けになります
NSKeyedArchiverは変化しています セキュアコーディングは プラットフォーム全体に導入され それをサポートする NSKeyedArchiver APIも 今年 劇的な変化を遂げています これは値変換の変化を意味します もし管理オブジェクトモデルの中に 変換可能なプロパティを持ち まだ値変換を送っていないなら 値変換はNSKeyedUnarchive FromDataTransformerが デフォルトになっています 今後はNSSecureUnarchive FromDataTransformerになります 実装されるセキュアコーディングは ぜひ導入すべきです これに関する講演が 今朝 実施されました “Data You Can Trust”です アプリケーションを より障害に強くするために 視聴することをお勧めします
モデルエディタの中で これを指定することもできます 使うのはValue Transformer Nameのフィールドです 今は皆さん自身で これを実装してほしいと思います これは将来 デフォルトになるでしょう また デフォルトのValue Transformer Nameを使っていれば Xcodeで 警告が出るようにもなります コードでモデルをビルドするなら valueTransformerNameプロパティを NSAttributeDescription上で 使ってください カスタムクラスを エンコードしていなければ これは透過的になるはずです plistタイプにとってはNOP命令です 単純にValue Transformer Nameを 変えれば 新しいセキュアコーディングの 動作を得られるでしょう しかし もしカスタムクラスを 実装しているなら それらのクラスには セキュアコーディングが必要です ラボに来ていただければ 力になります さらに有用なことがあります 私たちが注力してきたのは スタック下で何が起きているのかを 理解するのに役立つ― デバッグツールの開発です こちらはスキーム設定の画像です SQLiteのデバッグ情報が 増えるよう プロセスについて 議論を重ねています ここで非常に大事なのが com.apple.CoreData. ConcurrencyDebugです これはアプリケーションにおける キューの例外を捉えます メインとバックグラウンドの キューコンテキスト間で オブジェクトを移動させるエリア あるいは管理オブジェクトの 実際のコンテキストに 従わないエリアなどです
またSQLiteは興味深い環境変数を 多く有します それらのスレッドやアサーションは API周辺などにおける アプリケーションの正確性に 非常に役立つものです 自動トレースはバックグラウンドの 動作を把握するための デバッグログ上の手段です com.apple.Core Data. SQLDebugには 4つの段階があります 1つ目は最も興味深く パフォーマンスヒットは 最も小さくなります 4つ目の段階は 最も詳細な状態ですが パフォーマンスヒットを 非常に大きくします
SQLデバッグやマルチスレッドの アサーションを有効にすると コンソール内に ログを見ることができます これはアサーションが正常に 機能していることを示すものです SQLデバッグを有効にすると フェッチ要求のためのセレクト文や 所要時間が見られます 4つ目の段階では “EXPLAIN”が得られます それは与えられた セレクト文のための クエリプランを示します ここではテーブルスキャンを通して テーブルビューが選択されています タイムスタンプ上の ORDER BY用に メモリ内の一時的なB-treeを 使っています これは潜在的な パフォーマンスの問題です アプリケーションを動かす際は こうしたメッセージを利用して ムダのある箇所を確認できます 修正の方法は?
答えは SQLite 3にあります データベースを開き SQLログから セレクトクエリを渡せば エキスパートモードを 有効にできます これはクエリを分析して カバリングインデックスを作り 最適なソリューションを 与えてくれます モデルエディタの中で行うには ポストエンティティに フェッチインデックスを加えます タイムスタンプ上で 実行できるように設定し 降順にフェッチ 一番最近のポストを テーブルの トップに表示しているからです
アプリケーションを再び実行すると 同じセレクトログが見られます
今回はセレクトクエリが カバリングインデックスを クエリの際にヒットしています クエリはORDER BY用に カバリングインデックスを使います
R-treeを使う複合インデックスなど 様々な型のインデックスを サポートしています 様々なクエリを生成したり セレクト文内で境界ボックスを使う クエリを最適化したりする上で これらは非常に有効です 通常 ロケーションに応じて行われ 他のインデックスを ポストエンティティに加え設定 latitudeやlongitudeの中で 機能するインデックスです
R-treeを選択して ボックス内のクエリタイプを変更
するとフェッチ要求上に 述語を加えることができます “中国大陸内で起こる 全てのポストを得よ”と
この述語は セレクト文の中で 関数を使っているため 少し高度なものになっています 管理オブジェクトモデル内の インデックスをヒットするためです
この述語やインデックスなしに アプリケーションを実行する場合も 同じ結果を見ることができます そこではタイムスタンプの インデックスだけがヒットされます
一方 実行に 新しいインデックスと述語を使う時 SQLiteは そのインデックスを使い 間にあるコードに対し より速い結果を生成します
ただ タイムスタンプの インデックスは 境界を作る述語を 1つも持たないため SQLiteはそれを ソートに使えません
そこで選んだ最適化の方法は 複合インデックスを使い まず結果セットを 小さなオブジェクトのセットに変え ORDER BY用にインメモリで B-treeをソートすることです
ご覧のように このインデックスは フェッチのパフォーマンスを 約25%向上させます
このケースでは性能テストを 10万行以上にわたり行ったところ フェッチだけで 約130ミリ秒の改善が見られました
ここでCore Dataの テストの話に移りましょう ご存じかもしれませんが 私たちはテストが大好きです Core Dataでは 正確性と学習性の両方の観点で テストを行います Core Dataの機能や APIの動作を確認する上で重要です また Core Dataの機能に関し 仮説を検証する上でも有効です よりよい顧客体験のための 手助けとなるのです R-treeインデックスは たとえ インメモリでB-treeをソートしても パフォーマンスに 恩恵をもたらします
テストは動作環境を 把握する上でも大切です 皆さんが何を求めているかが 分かるからです 皆さんが顧客のために どんな動作を望んでいるのかは テストで明らかにできます これを自力で簡単に行うために 重要なものがあります 例えば永続コンテナを生成する ベースクラスなどです こちらのベースクラスは たまたま永続ストア用の /dev/nullのURLを使っています これによりテストは 小さな 管理オブジェクトのセット上で 非常に素早く行われます 全てメモリの中で 行われるからです この時 SQLiteは インメモリストアを実現させます 非常に効率的ですが インメモリなので データ量次第ではテストスイートの メモリを増大させてしまいます
ストアファイルをディスク上に 具現化するテストは 少なくとも1回は実行すべきです 皆さんがテストスイート用の ストアを開けない場合 顧客もそれを開けない可能性が 高いからです
アプリケーションデリゲート内に 永続コンテナがあるのなら コンテナを取り上げ ストアに 直接書き込める― テストベースクラスを持てます しかしその場合 皆さんが 書き込んでいるストアファイルは アプリケーションによって 使用されているため注意が必要です もし 個人のデバイスで テストを実行するなら 次にアプリケーションを開いた時 その効果が分かるでしょう
10万件のレコードを7行のコードで 挿入できるとしたら?
これは練習問題として あとに取っておくつもりでしたが こうしたスキャフォールディングが 可能にするのは データ回りの不変性を評価する テストスイートの構築です これらのメソッドを 前もってビルドしておくことで 例えばデータが変化した際も 繰り返し使うことができます オブジェクトグラフ用の仕組みや 新しいエッジクラスをビルドしたり パフォーマンスなど バックグラウンドの特定の動作を 評価したりするためです
R-treeクエリの性能テストで使った 単体テストのスキャフォールドです フェッチのパフォーマンスは 数行のコードで 確実なものにできます Core Dataの特徴や機能間の トレードオフを評価する上で こうしたテストは非常に役立ちます
この3行のコードが生成するのは テストで使うための 新しい管理オブジェクト コンテキストと コンテナです これは極めて重要です テストにおけるセットアップと テアダウンのロジックは 時にそのパフォーマンスに 影響を及ぼすからです 自分が今 テストしているのは テアダウンのパフォーマンスか セットアップのパフォーマンスか クエリのランタイムかなど 分析しましょう
テストが終わると バグを報告できます
バグは大歓迎です よりよいアプリケーションのために 必要なものですからね しかし バグの報告にあたり テストやサンプルAppがないと 対処が非常に困難です 先ほど話したように 皆さんの動作環境や要望は 緻密なテストによってこそ 正確に把握できます 実際 テストスイートを有する アプリケーションや 皆さんの懸念事項が明確な サンプルがあるだけで 私たちは いち早くレスポンスできます そして対処法を お伝えすることができるのです またテストは 修復の正確性の 検証にも役立ちます バグ報告の際は まずはテストを 書くようにしてください
本日は以上です
明日はTechnology Lab 7にて 1時半からお待ちしています 明日のTesting Tips & Tricksも ぜひご覧ください
ありがとう (拍手)
-